
Вы здесь ▸ Исследования ▸

Продолжаю оценивать качество резюме текста с помощью модели Doc2Vec библиотеки Gensim
Я продолжаю эксперименты, позволяющие оценить качество резюмирования текста. Метод, который является предметом экспериментов – это вычисление семантического сходства текстов с помощью модели Doc2Vec библиотеки Gensim. При этом появляется возможность получить количественное значение показателя степени отражения в резюме основных мыслей исходного документа. В данном материале я повторяю серию экспериментов, описанных ранее, но с другими данными. Этими данными является исходный документ и несколько резюме, сгенерированные различными языковыми моделями.

Новая задача
Настройка и обучение Doc2Vec
Результаты оценки качества резюме
Обсуждение результатов
Примечания
И что дальше?
Новая задача
Здесь описывалось решение задачи оценки семантического сходства каждого из 13-ти резюме, сгенерированных различными алгоритмами, с текстом исходного стихотворения А.А. Блока. В результате мы определили качество резюмирования и сравнили с субъективными (пока только моими) оценками. Для решения задачи использовалась модель Doc2Vec библиотеки Gensim. Ниже описывается решение той же задачи, но с другими текстами, с которыми я также работал при сравнении моделей для резюмирования текстов [1, 2, 3]. Это текст общего описания приложения Текстоматика и тексты 13-ти резюме, сгенерированных теми же алгоритмами.
Настройка и обучение Doc2Vec
Наборы данных для обучения модели:
- DS1 – исходный текст и тексты всех сгенерированных резюме (14 документов).
- DS2 – тексты DS1 и текст статьи той же тематики (1 документ).
- DS3 – тексты DS2 и текст другой статьи той же тематики (1 документ).
- DS4 – тексты DS3 и текст третьей статьи той же тематики (1 документ).
- DS5 – тексты DS4 и тексты статей из Википедии: [1], [2], [3], [4] (4 документа).
Эти пять наборов данных (всего 21 документ) были использованы для подбора значений гиперпараметров модели. Основные гиперпараметры следующие: количество итераций процедуры обучения (эпох) – 200, размер вектора документа – 300, минимальная частота активных слов – 2, скорость обучения – 0.025.
Процедура подготовки исходных данных, обучения и оценки качества модели стандартные для Doc2Vec. Как и в первой части исследования, я не привожу здесь исходных кодов на Python. Они достаточно просты и соответствуют руководствам разработчиков.
Результаты оценки качества резюме
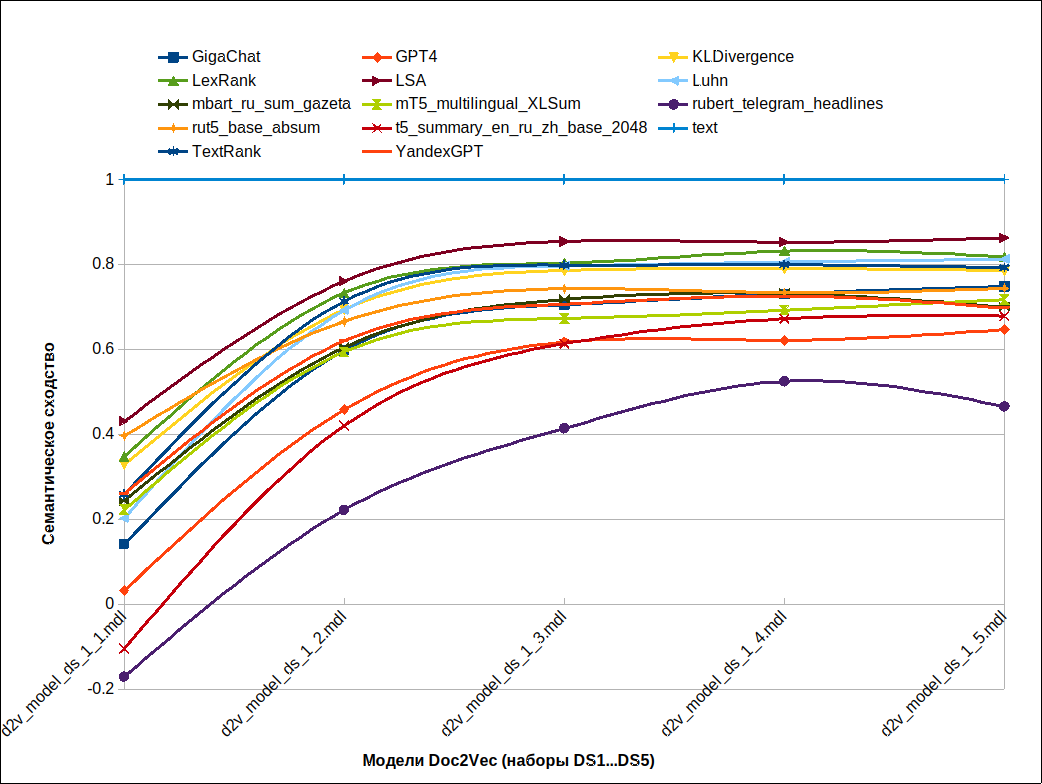
Обсуждение результатов
- На графике видно, что, начиная с набора DS3 (модель оценки резюме d2v_model_ds_1_3.mdl), значение показателя сходства резюме и исходного текста стабилизируется.
- Разброс значений показателя семантического сходства резюме и исходного текста для всех моделей (за исключением rubert_telegram_headlines) не велик: в пределах 0.2.
- Первые пять мест по убыванию эффективности заняли модели sumy : LSA, LexRank, Luhn, TextRank, KL Divergence. Мои оценки в исследовании: LexRank – 4, Luhn – 3, LSA – 2, TextRank – 2, KL Divergence – 2. Недооценил LSA, остальное полностью совпадает. Все-таки нужна статистика по экспертным оценкам.
- По группе специализированных нейросетей для суммаризации текста порядок по убыванию эффективности следующий: rut5_base_absum, mT5_multilingual_XLSum, mbart_ru_sum_gazeta, t5_summary_en_ru_zh_base_2048, rubert_telegram_headlines. Мои оценки в исследовании: mbart_ru_sum_gazeta – 3, rut5_base_absum – 3, mT5_multilingual_XLSum – 2, t5_summary_en_ru_zh_base_2048 – 2, rubert_telegram_headlines – 1. Здесь я переоценил mbart_ru_sum_gazeta, остальное полностью совпадает. Аналогично предыдущему пункту – нужна статистика по экспертным оценкам.
- По группе LLM порядок по убыванию эффективности следующий: GigaChat, YandexGPT, GPT4. Моя оценка в исследовании:GPT4 – 5, GigaChat – 4, YandexGPT – 3. Статистика по экспертам!
- Несмотря на то, что значения оценок близки, адекватная дифференциация возможна. Это дает основание использовать подход Gensim + Doc2Vec для оценки качества суммаризации текстов.
Примечания
Модель Doc2Veb уже использовалась мною при разработке приложения Текстоматика. Показатели качества текстов Соответствие содержания и Семантическое сходство вычисляются с ее помощью.
Также отмечу актуальность используемых инструментов. На YandexGPT ответил: Библиотека Gensim действительно современная и активно используется в области анализа текста. Она предоставляет инструменты для обработки естественного языка, тематического моделирования и других задач.
И что дальше?
Мы убедились, что использование Gensim + Doc2Vec для оценки качества суммаризации текстов дает результаты. Насколько можно им доверять? Чтобы проверить это мы должны:
- Увидеть влияние гиперпараметров модели Doc2Veb на качество ее обучения. И подобрать лучшие их сочетания.
- Количественно оценить эффективность обученной модели Doc2Veb при вычислении показателя семантического сходства текстов.