
Вы здесь ▸ Технологии и инструменты ▸

Оценка качества резюме текста с помощью модели Doc2Vec библиотеки Gensim
Когда мы с помощью каких-либо алгоритмов получаем резюме текста, то возникает естественный вопрос о качестве этого резюме. Конечно, качество можно оценить визуально, прочитав текст резюме. Но какова вероятность того, что все важные аспекты, суть текста отражена в резюме? Очевидно, что эта вероятность не 100%. Должны быть способы оценки суммирующего текста, позволяющие понять степень отражения основных мыслей исходного документа. И обосновать почему сформирована такая оценка. В материале ниже я описываю метод оценивания качества резюме путем вычисления семантического сходства текстов с помощью модели Doc2Vec библиотеки Gensim.

Семантическое сходство документов
Модель Doc2Vec библиотеки Gensim
Исходные тексты
Какую задачу решали?
Настройка и обучение Doc2Vec
Результаты оценки качества резюме
Обсуждение результатов
Примечания
Что дальше?
Семантическое сходство документов
Идея заключается в сравнении семантики исходного документа и его резюме. Для этого целесообразно использовать семантическое сходство – количественную метрику, в основе которой лежит расстояние между документами. Причем расстояние должно вычисляться, исходя из семантики (смысла) единиц текста таких как слова, параграфы, разделы и т.п. Эти задачи эффективно решаются с помощью модели Doc2Vec библиотеки Gensim.
Модель Doc2Vec библиотеки Gensim
Gensim – это бесплатная библиотека Python с открытым исходным кодом для представления документов в виде семантических векторов. Gensim предназначен для обработки необработанных, неструктурированных цифровых текстов (“обычный текстов”) с использованием алгоритмов машинного обучения без учителя.
Алгоритмы в Gensim, такие как Doc2Vec и др. автоматически определяют семантическую структуру документов, исследуя статистические закономерности совпадения в корпусе обучающих документов. Вмешательства человека не требуется, нужен только набор обычных текстовых документов. В результате для обработанных документов могут быть семантическом представлении и запрошены на предмет тематического сходства с другими документами (словами, фразами…).
Полностью библиотека Gensim и модель машинного обучения Doc2Vec, поддерживаемая ею, описаны здесь.
Исходные тексты
Рассмотрим для примера тексты, с которыми я работал при сравнении моделей для резюмирования текстов [1, 2, 3]. А именно стихотворение А.А. Блока “О подвигах, о доблести, о славе…” и тексты 13-ти резюме, сгенерированных различными алгоритмами.
Какую задачу решали?
Задача заключалась в оценке семантического сходства каждого резюме с текстом исходного стихотворения. Далее сравнивались полученные количественные значения. Тем самым мы определили качество резюмирования и сравнили с субъективными (пока только моими) оценками.
Настройка и обучение Doc2Vec
Наборы данных для обучения модели:
- DS1 – исходный текст и тексты всех сгенерированных резюме (14 документов).
- DS2 – тексты DS1 и еще 129 стихотворений Блока (143 документа).
- DS3 – тексты DS2 и еще 67 стихотворений Блока (210 документов).
- DS4 – тексты DS3 и еще 43 стихотворения Блока (253 документа).
- DS5 – тексты DS4 и еще 98 стихотворений Блока (351 документ).
Пять наборов данных были использованы для оптимизации значений гиперпараметров модели. Основные гиперпараметры следующие: количество итераций процедуры обучения (эпох) – 200, размер вектора документа – 300, минимальная частота активных слов – 2, скорость обучения – 0.025.
Процедура подготовки исходных данных, обучения и оценки качества модели стандартные. Я не привожу здесь исходных кодов на Python. Они достаточно просты и соответствуют руководствам разработчиков.
Результаты оценки качества резюме
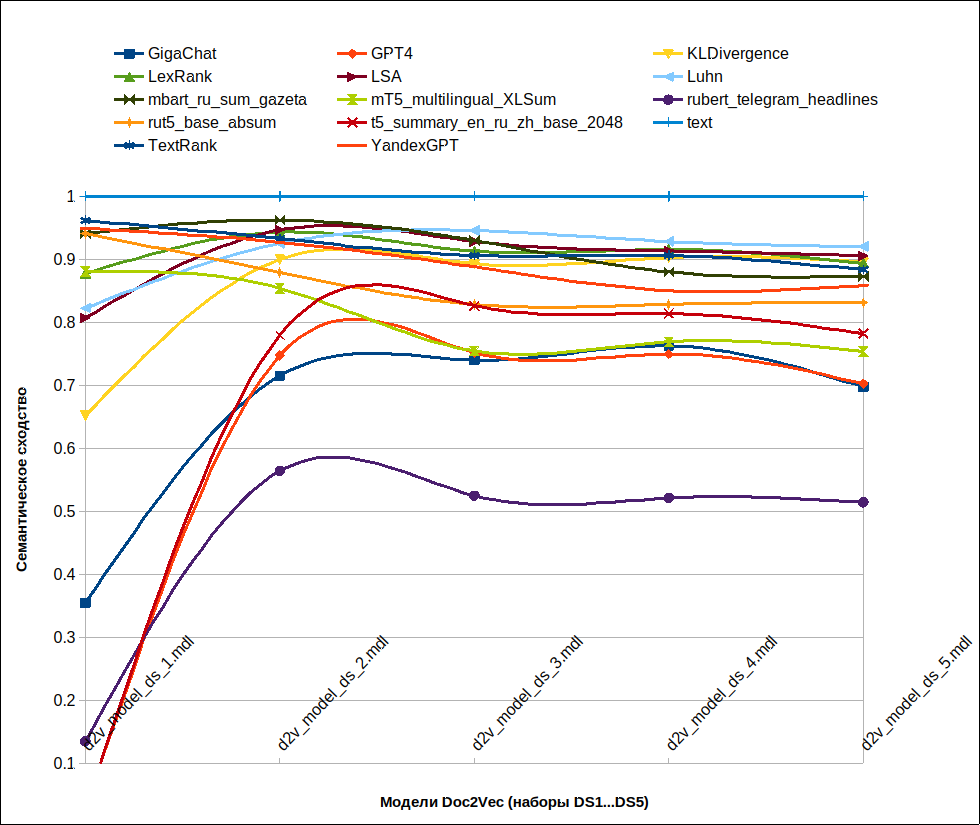
Обсуждение результатов
- На графике видно, что, начиная с набора DS2 (модель оценки резюме d2v_model_ds_2.mdl), значение показателя сходства резюме и исходного текста стабилизируется. Однако, для более точного обоснования результатов требуются дополнительная настройка гиперпараметров Doc2Vec и корректная оценка ее качества.
- По группе специализированных нейросетей для суммаризации текста порядок по убыванию эффективности следующий: mbart_ru_sum_gazeta (с большим отрывом), rut5_base_absum, t5_summary_en_ru_zh_base_2048, mT5_multilingual_XLSum, rubert_telegram_headlines (с большим отрывом). Практическое совпадение с моими оценками: mbart_ru_sum_gazeta – 3, rut5_base_absum – 2, mT5_multilingual_XLSum – 3, t5_summary_en_ru_zh_base_2048 – 2, rubert_telegram_headlines – 1.
- По группе LLM порядок по убыванию эффективности следующий: YandexGPT, GigaChat, GPT4 (две последних модели показали практически одинаковые результаты). Моя оценка зеркальная GigaChat – 5, GPT4 – 5, YandexGPT – 3. Объяснение простое и я писал об этом ранее: “GigaChat рассказал историю главного героя. GPT4 передал чувства героя. А YandexGPT просто пересказал содержание стихотворения, сократив исходные фразы“. Поэтому, для того, чтобы уловить семантическое сходство резюме GigaChat или GPT4 и исходного стихотворения, необходимо глубокое обучение Doc2Vec.
- По группе моделей sumy порядок моделей установить проблематично; разброс значений находится в диапазоне 0…0.05. При этом для разных наборов данных порядок, как правило, различен. Моя оценка примерна такая же: LSA – 5, TextRank – 5, Luhn – 4, LexRank – 4, KL Divergence – 4.
Таким образом, в целом мы видим вполне адекватные результаты, показанные Gensim + Doc2Vec. Что дает основание использовать этот подход для оценки качества суммаризации текстов.
Примечания
Надо сказать, что модель Doc2Veb уже использовалась мною при разработке приложения Текстоматика. Показатели качества текстов Соответствие содержания и Семантическое сходство вычисляются с ее помощью.
Также отмечу актуальность используемых инструментов. На соответствующий вопрос ИИ ChatGPT ответил: Gensim является современной и актуальной. Последняя версия – 4.2.0, выпущенная 29 апреля 2022 года, обладает улучшенной производительностью и функциональностью. Рекомендуется использовать эту версию для анализа текстовых документов.
Что дальше?
А дальше вот что:
- Есть смысл повторить эксперименты на других данных, из другой предметной области.
- Интересно увидеть динамику гиперпараметров модели Doc2Veb. А потом выбрать лучшие значения.
- Хорошо бы проверить качество обученной модели Doc2Veb и убедиться тем самым в достоверности результатов.