
Вы здесь ▸ Исследования ▸

Обучение модели Doc2Vec. Как проверить ее качество?
Ранее в [1], [2] мы убедились, что использование модели Gensim + Doc2Vec для оценки качества резюмирования (или суммаризации, автореферирования) текста дает результаты. Но насколько можно доверять этим результатам? Для того, чтобы проверить это, мы прежде всего должны убедиться в том, что модель обучена так, как надо. Это означает, что мы имеем приемлемые значения показателя качества обучения, которые обеспечиваются наилучшим сочетанием значений гиперпараметров модели. Ниже описываются результаты мини-исследования влияния одного из гиперпараметров – количества итераций (“эпох”) – на качество обучения модели Doc2Vec.

Функция потерь
Реализация вычислений
Исходные данные
Результаты
Обсуждение результатов
Итоги
Функция потерь
Эта функция должна оценивать расхождение между предсказаниями модели и фактическими значениями. Для модели Doc2Vec определить функцию потерь не так просто. У нас есть предсказанные эмбеддинги – векторы документов, но нет и быть не может фактических векторов. Обучение модели происходит самонастраивающимися алгоритмами (обучение “без учителя”), поэтому нет эталонных эмбеддингов. Как же быть? Разработчики предлагают следующий вариант:
- Исходное предположение – обучающий корпус документов это какие-то новые данные.
- Далее генерируем с помощью модели новые векторы для каждого документа обучающего корпуса.
- Сравниваем полученные векторы с векторами тех же самых документов, которые входят в модель.
- Вычисляем ранги документов: 0 – документ наиболее похож на самого себя, 1 – документ наиболее похож на другой документ.
- Вычисляем степень сходства данного документа и а) документа, наиболее похожего на данный и б) документа, следующего за самым похожим на данный. Ожидается, что степень сходства со вторым по похожести документом должна значительно отличаться от степени сходства с самым похожим документом.
Очевидно, что если все документы имеют ранг 0, то модель обучена как надо. То есть, невозможно обучить модель лучше при ее оценке по данному показателю.
Дополним предложенный выше порядок вычислений:
- Функция потерь L может быть вычислена следующим образом:
L=N_0/N=1-N_1/N,
где N – общее количество документов, N0 и N1 – количество документов с рангом 0 и 1 соответственно.
- Вычисление медианы и наименьшей степени сходства документов.
Реализация вычислений
Обучение модели doc2vec (фрагмент кода)
...
srcdata = [...]
traindocids = [...]
...
model = gensim.models.doc2vec.Doc2Vec(vector_size=vectorsize, min_count=mincount, epochs=epochs, alpha=alpha, min_alpha=min_alpha)
...
train_data = list(create_tagged_document(srcdata, traindocids))
if len(train_data) > 0:
if isinstance(model, gensim.models.doc2vec.Doc2Vec):
model.build_vocab(train_data)
model.train(train_data, total_examples=total_examples, epochs=model.epochs, callbacks=[d2vEpochAssessment(self, srcdata, traindocids)])
...Вычисление функции потерь (фрагмент кода)
class d2vEpochAssessment(CallbackAny2Vec):
# Callback to compute assess rank after each epoch.
def __init__(self, parent, docs, docids, shift = 50):
self.epoch = 1
self.docs = docs
self.docids = docids
self.parent = parent # Class that implements model training.
self.shift = shift
def on_epoch_end(self, model):
if (self.epoch % self.shift) == 0 or self.epoch == 1:
losses, most_similarities = self.parent.getloss(epoch = self.epoch, docs = self.docs, docids = self.docids)
self.epoch += 1
def getloss(self, epoch = 0, docs = [], docids = [], d2v_model = None, most_topn = 0):
ranks = []
most_similarities = []
train_corpus = docs
model = self.parent.model if d2v_model == None else d2v_model
epoch = self.parent.model.epochs if epoch == 0 else epoch
topn = len(model.dv) if most_topn == 0 else most_topn
for i, doc_id in enumerate(docids):
inferred_vector = model.infer_vector(train_corpus[i])
sims = model.dv.most_similar(inferred_vector, topn=topn)
ids = [docid for docid, sim in sims]
rank = ids.index(doc_id)
ranks.append(rank)
most_similarities.append(sims)
counter = collections.Counter(ranks)
loss = round(1 - counter[0] / len(docs), 3)
epochs = []
if len(self.parent.losses) > 0:
epochs = [value[0] for value in self.parent.losses]
if epoch not in epochs:
self.parent.losses.append([epoch, loss, dict(counter)])
return self.parent.losses, most_similarities Исходные данные
В ходе проведенных экспериментов обучались пять моделей Doc2Vec. Их имена: d2v_model_ds_1_1, d2v_model_ds_1_2, d2v_model_ds_1_3, d2v_model_ds_1_4, d2v_model_ds_1_5. Для каждой из них был подготовлен соответствующий обучающий набор: DS1, DS2, DS3, DS4 и DS5. Описание обучающих наборов можно увидеть здесь. Основные гиперпараметры модели следующие: количество итераций процедуры обучения (эпох) – 1000, размер вектора документа – 300, минимальная частота активных слов – 2, скорость обучения – 0.025. Процедура подготовки исходных данных и обучения стандартные для Doc2Vec.
Результаты
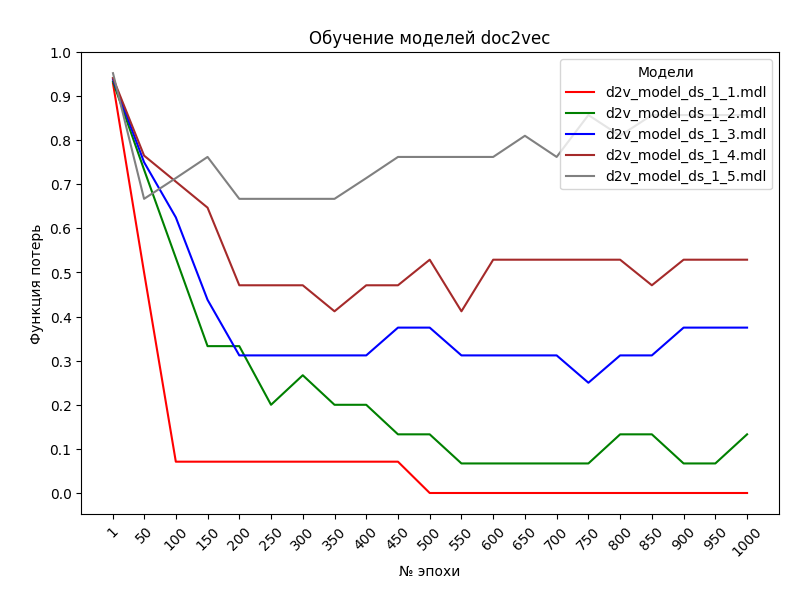
На рисунке представлены изменения функции потерь L от количества эпох при обучении пяти моделей, упомянутых выше.
А вот статистические данные по результатам обучения (даны средние значения по всем документам обучающего набора модели):
| Модель doc2vec | Наилучшее сходство | Второе сходство | Наихудшее сходство | Медиана |
|---|---|---|---|---|
| d2v_model_ds_1_1.mdl | 0.968 | 0.664 | 0.26 | 0.487 |
| d2v_model_ds_1_2.mdl | 0.974 | 0.803 | 0.496 | 0.687 |
| d2v_model_ds_1_3.mdl | 0.973 | 0.831 | 0.625 | 0.742 |
| d2v_model_ds_1_4.mdl | 0.973 | 0.838 | 0.632 | 0.751 |
| d2v_model_ds_1_5.mdl | 0.982 | 0.859 | 0.703 | 0.778 |
Обсуждение результатов
- Из графиков на рисунке выше видно, что лучше всего обучилась модель d2v_model_ds_1_1 с набором DS1. Начиная с эпох с номерами около 500 эпох, потери равны 0. При этом изменение (уменьшение) потерь происходит достаточно плавно, без выбросов. Второе по величине среднее сходство данного документа с документами обучающего набора составляет 0,69 от среднего сходства документа с самим собой. Не скажу, что значительно, но значимо.
- Несколько худшие, но приемлемые результаты показывает модель d2v_model_ds_1_2 с набором DS2. В диапазоне номеров эпох 500-550 потери стабилизируются на уровне ≈0.1. Второе сходство составляет 0.82 от среднего сходства документа с самим собой. Не до конца убедительно.
- Модели d2v_model_ds_1_3 и d2v_model_ds_1_4 не продемонстрировали надлежащего снижения потерь. Стабилизация на уровне 0.3-.5 наступила с эпох с номерами около 200. Слабое утешение – меньшее количество эпох. Второе сходство составляет 0.85-0.86 от среднего сходства документа с самим собой. Еще более неубедительно.
- Дополнительно, модели d2v_model_ds_1_4 и d2v_model_ds_1_5 имеют склонность к переобучению. Начиная с эпох с номерами около 350-400, потери начинают возрастать. Второе сходство тоже – до 0.88 от сходства документа с самим собой.
- Можно сделать предварительный вывод о минимально необходимом количестве эпох для обучения моделей – 400.
- Несколько неожиданны результаты для моделей d2v_model_ds_1_3, d2v_model_ds_1_4 и d2v_model_ds_1_5. Ожидалось более качественное обучение для наборов с большим количеством документов. Предположительная причина такой ситуации – влияние других гиперпараметров.
Итоги
Очевидна необходимость продолжить исследование для понимания того, как оценить качество обучения модели Doc2Vec. Направление работы – анализ влияния размера вектора документа, минимальной частоты активных слов, скорости обучения на значение функции потерь. Чем и займемся в ближайшее время.