
Вы здесь ▸ Образование ▸

Дорожная карта для подготовки специалиста – исследователя данных
Дорожная карта исследователя данных предназначена для упорядочивания подготовки (или самоподготовки) таких специалистов. Она позволяет выделить основные разделы учебных курсов по data science, назначить приоритеты, определить порядок изучения и освоения, распланировать время. Ниже кратко описывается содержание маршрутов этой дорожной карты, Названия тем даны на русском языке с их английскими эквивалентами. Раздел “Основы” (Fundamentals) расписан более подробно, что соответствует направленности и контенту этого сайта.

Дорожная карта
Вот она:
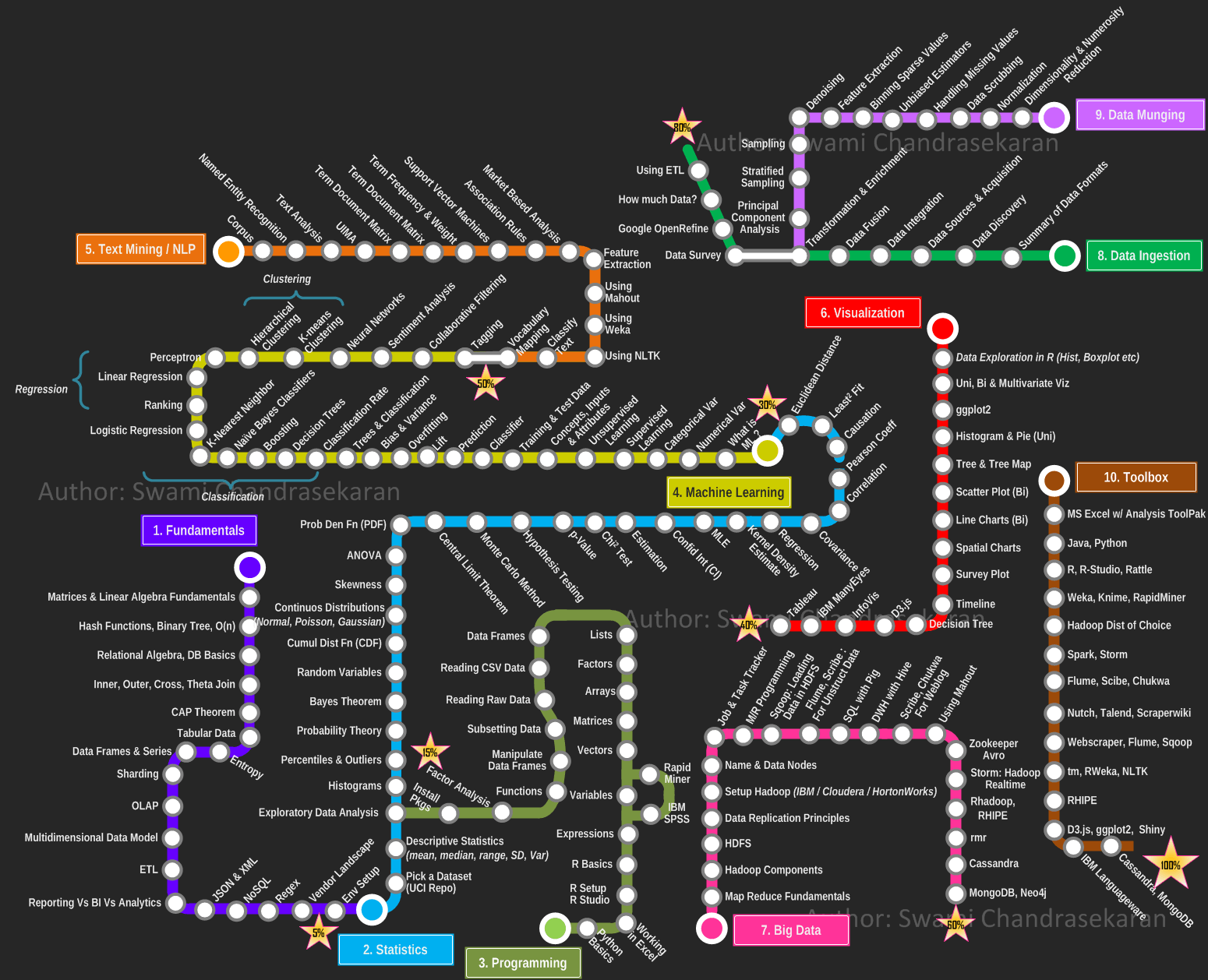
Похожа на схему метро, не так ли?
Дорожная карта исследователя данных состоит из разделов, каждый из которых включает ключевые темы. Для раздела “Основы” я привожу краткое содержание тем, для остальных разделов только названия тем.
В математике матрица – это прямоугольный массив чисел, символов или выражений, расположенных в строках и столбцах. Матрица может быть преобразована в свою подматрицу путем удаления любого набора строк и/или столбцов.
Существует ряд основных операций, которые могут быть применены к матрицам:
Хэш-функция – это любая функция, которая может использоваться для сопоставления данных произвольного размера с данными фиксированного размера. Одним из применений является структура данных, называемая хэш-таблицей, широко используемая в компьютерных программах для быстрого поиска данных. Хэш-функции ускоряют поиск в таблице или базе данных.
В информатике бинарное дерево – это древовидная структура данных, в которой каждый узел имеет не более двух дочерних элементов, которые называются левым дочерним элементом и правым дочерним элементом.
Нотация O используется для классификации алгоритмов в соответствии с тем, как возрастают требования к времени их выполнения или объему данных по мере увеличения размера входных данных. В аналитической теории чисел нотация O часто используется для выражения оценки разницы между арифметической функцией и более понятным приближением.
Основное приложение реляционной алгебры заключается в создании теоретической основы для реляционных баз данных, в частности языков запросов к ним, главным из которых является SQL.
Базовым понятием реляционной алгебры является естественное соединение. В языке SQL, естественное соединение между двумя таблицами будет выполнено, если:
- По крайней мере один столбец в обеих таблицах имеет одинаковое имя.
- Эти два столбца имеют одинаковый тип данных:
- CHAR (символ)
- INT (целое число)
- FLOAT (числовые данные с плавающей запятой)
- VARCHAR (длинная цепочка символов)
SQL-запрос для естественного соединения (mySQL):
SELECT <COLUMNS>FROM <TABLE_1>NATURAL JOIN <TABLE_2>
SELECT <COLUMNS>FROM <TABLE_1>, <TABLE_2>WHERE TABLE_1.ID = TABLE_2.IDInner join. В SQL фраза INNER JOIN выбирает записи, которые имеют совпадающие значения в обеих таблицах:
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;Outer join. В SQL фраза FULL OUTER JOIN возвращает все записи, если есть совпадение либо в левой (table1), либо в правой (table2) записях таблицы:
SELECT column_name(s) FROM table1 FULL OUTER JOIN table2 ON table1.column_name = table2.column_name; Left join. В SQL фраза LEFT JOIN возвращает все записи из левой таблицы (table1) и совпадающие записи из правой таблицы (table2). Результат равен нулю с правой стороны, если совпадения нет:
SELECT column_name(s) FROM table1 LEFT JOIN table2 ON table1.column_name = table2.column_name;Right join. В SQL фраза RIGHT JOIN возвращает все записи из правой таблицы (table2) и совпадающие записи из левой таблицы (table1). Результат равен нулю с левой стороны, если совпадения нет:
SELECT column_name(s) FROM table1 RIGHT JOIN table2 ON table1.column_name = table2.column_name;Теорема CAP – утверждение о том, что в распределённых системах нельзя одновременно добиться трёх свойств:
- Consistency — на всех не отказавших узлах одинаковые (с точки зрения пользователя) данные.
- Availability — запросы ко всем не отказавшим узлам возвращают ответ.
- Partition tolerance — даже если связь в системе стала нестабильной (вплоть до разделения системы на куски), но узлы работают, то система в целом продолжает работать.
Другими словами, теорема CAP утверждает, что в распределенных системах приходится выбирать между согласованностью и доступностью.
Табличные данные отличаются от данных, содержащихся в реляционных базах данных SQL.
В табличных данных все упорядочено по столбцам и строкам. Каждая строка содержит одинаковый номер столбца (за исключением пропущенного значения, которое может быть заменено на “Нет”). Первая строка табличных данных в большинстве случаев является заголовком, описывающим содержимое каждого столбца.
Наиболее часто используемый формат табличных данных в data science – CSV. Каждый столбец окружен символом (таблица, запятая, …), отделяющим этот столбец от двух соседних.
Энтропия – это мера неопределенности. Высокая энтропия означает, что данные имеют высокую дисперсию и, следовательно, содержат много информации и/или шума.
Например, функция, где f (x) = 4 для всех x, не имеет энтропии и легко предсказуема, содержит мало информации, не содержит шума и может быть представлена в сжатом виде. Аналогично, f (x) = ~ 4 имеет некоторую энтропию, а f (x) = <случайное число> имеет очень высокую энтропию из-за шума.
Фрейм данных используется для хранения таблиц данных. Это список векторов одинаковой длины.
Ряд – это последовательность упорядоченных точек данных.
Сегментирование – это горизонтальное (по строкам) разделение базы данных, в отличие от вертикального (по столбцам) разделения, которое называется Нормализацией.
Зачем использовать сегментирование?
Системы баз данных с большими наборами данных или приложения с высокой пропускной способностью могут создавать проблемы с пропускной способностью одного сервера. Существует два способа решения проблемы роста: вертикальное и горизонтальное масштабирование.
Вертикальное масштабирование. Предполагает увеличение пропускной способности одного сервера. Но из-за технологических и экономических ограничений одной машины может быть недостаточно для данной рабочей нагрузки.
Горизонтальное масштабирование. Предполагает разделение набора данных и нагрузки на несколько серверов, добавление дополнительных серверов для увеличения пропускной способности по мере необходимости Хотя общая скорость или пропускная способность одной машины могут быть невысокими, каждая машина обрабатывает часть общей рабочей нагрузки, что потенциально обеспечивает большую эффективность, чем один высокоскоростной сервер с высокой пропускной способностью.
Идея состоит в том, чтобы использовать концепции распределенных систем для достижения масштабируемости. Но это сопряжено с теми же компромиссами повышенной сложности, которые присущи распределенным системам. Многие системы баз данных обеспечивают горизонтальное масштабирование посредством сегментирования наборов данных.
Оперативная аналитическая обработка, или OLAP (OnLine Analytical Processing), – это подход к быстрому выполнению многомерных аналитических запросов (MDA) в вычислительной технике.
OLAP является частью более широкой категории бизнес-аналитики, которая также включает в себя реляционные базы данных, написание отчетов и интеллектуальный анализ данных. Типичные области применения OLAP включают бизнес-отчетность для целей продаж, маркетинга, управленческую отчетность, управление бизнес-процессами (BPM), бюджетирование и прогнозирование, финансовую отчетность и аналогичные области, а также новые приложения, такие как сельское хозяйство.
Термин OLAP был создан по аналогии с традиционным термином баз данных: ОnLine Transaction Processing (OLTP).
- Извлечение (Extract)
- извлечение данных из нескольких разнородных систем-источников;
- проверка данных для подтверждения того, что извлеченные данные имеют правильные/ожидаемые значения в данной предметной области;
- Преобразование (Transform)
- извлеченные данные передаются в конвейер, который применяет множество функций для обработки данных;
- эти функции предназначены для преобразования данных в формат, приемлемый для конечной системы;
- включает в себя очистку данных для удаления шума, аномалий и лишних данных;
- Загрузка (Load)
- загружает преобразованные данные в конечный целевой объект.
JavaScript Object Notation (JSON) – это не зависящий от языка формат данных. Пример, описывающий человека:
{"firstName": "John","lastName": "Smith","isAlive": true,"age": 25,"address": {"streetAddress": "21 2nd Street","city": "New York","state": "NY","postalCode": "10021-3100"},"phoneNumbers": [{"type": "home","number": "212 555-1234"},{"type": "office","number": "646 555-4567"},{"type": "mobile","number": "123 456-7890"}],"children": [],"spouse": null}
Extensible Markup Language (XML) – это язык разметки, который определяет набор правил для кодирования документов в формате, удобочитаемом как человеком, так и машиной.
<CATALOG><PLANT><COMMON>Bloodroot</COMMON><BOTANICAL>Sanguinaria canadensis</BOTANICAL><ZONE>4</ZONE><LIGHT>Mostly Shady</LIGHT><PRICE>$2.44</PRICE><AVAILABILITY>031599</AVAILABILITY></PLANT><PLANT><COMMON>Columbine</COMMON><BOTANICAL>Aquilegia canadensis</BOTANICAL><ZONE>3</ZONE><LIGHT>Mostly Shady</LIGHT><PRICE>$9.37</PRICE><AVAILABILITY>030699</AVAILABILITY></PLANT><PLANT><COMMON>Marsh Marigold</COMMON><BOTANICAL>Caltha palustris</BOTANICAL><ZONE>4</ZONE><LIGHT>Mostly Sunny</LIGHT><PRICE>$6.81</PRICE><AVAILABILITY>051799</AVAILABILITY></PLANT></CATALOG>
Базы данных NoSQL отличаются от реляционных баз данных (NoSQL расшифровывается как Not Only SQL). Данные не структурированы, и между таблицами нет понятия ключей.
В базе данных NoSQL можно хранить любые данные (JSON, CSV, …), не задумываясь о сложной схеме взаимодействия.
Наиболее популярные NoSQL СУБД: Cassandra, MongoDB, Redis, Oracle NoSQL.
Регулярные выражения (regex) широко используются в информатике. Их можно использовать в широком диапазоне возможностей:
- Для замены текста
- Для извлечения информации из текста (адрес электронной почты, номер телефона и т.д.)
- Для отображения текстовых файлов
http://regexr.com – хороший веб-сайт для экспериментов с регулярными выражениями.
Для использования регулярных выражений в Python достаточно указать:
import re- Выбор набора данных (Pick a dataset)
- Описательная статистика (Descriptive statistics)
- Предварительный анализ данных (Exploratory data analysis)
- Гистограммы (Histograms)
- Процентили и выбросы (Percentiles & outliers)
- Теория вероятностей (Probability theory)
- Теорема Байеса (Bayes theorem)
- Кумулятивно-дисперсионный анализ (Cumul Dist Fn: CDF)
- Непрерывные распределения (Continuous distributions)
- Асимметрия (Skewness)
- Дисперсионный анализ (ANOVA)
- Вероятностный анализ (Prob Den Fn: PDF)
- Метод Монте-Карло (Monte Carlo method)
- Проверка гипотез (Hypothesis Testing)
- P-значение (p-Value)
- Критерий хи-квадрат (Chi2 test)
- Оценка (Estimation)
- Доверительный интервал (Confid Int: CI)
- Метод максимального правдоподобия (Maximum Likelihood Estimation: MLE)
- Ядерная оценка плотности (Kernel Density estimate)
- Регрессия (Regression)
- Ковариация (Covariance)
- Корреляция (Correlation)
- Причинность (Causation)
- Метод наименьших квадратов (Least2-fit)
- Евклидово расстояние (Euclidean Distance)
- Основы Python (Python Basics)
- Работа в Excel (Working in Excel)
- Настройка R/R studio (Setup R/R studio)
- Основы R (R basics)
- Выражения (Expressions)
- Переменные (Variables)
- IBM SPSS (IBM SPSS)
- RapidMiner
- Векторы (Vectors)
- Матрицы (Matrices)
- Массивы (Arrays)
- Факторы (Factors)
- Списки (Lists)
- Фреймы данных (Data frames)
- Чтение CSV-данных (Reading CSV data)
- Чтение необработанных данных (Reading raw data)
- Подстановка данных (Subsetting data)
- Манипулирование фреймами данных (Manipulate data frames)
- Функции (Functions)
- Факторный анализ (Factor analysis)
- Установка (PKGS Install PKGS)
- Что такое ML? (What is ML?)
- Числовые переменные (Numerical var)
- Категориальные переменные (Categorical var)
- Контролируемое обучение (Supervised learning)
- Неконтролируемое обучение (Unsupervised learning)
- Концепции, входные данные и атрибуты (Concepts, inputs and attributes)
- Данные для обучения и тестирования (Training and test data)
- Классификаторы (Classifiers)
- Прогнозирование (Prediction)
- Повышение эффективности (Lift)
- Переобучение (Overfitting)
- Смещение и дисперсия (Bias & Variance)
- Дерево и классификация (Tree and Classification)
- Скорость классификации (Classification rate)
- Дерево решений (Decision tree)
- Повышение эффективности (Boosting)
- Наивные байесовские классификаторы (Naives Bayes classifiers)
- Алгоритм KNN (K-Nearest neighbor)
- Логистическая регрессия (Logistic regression)
- Ранжирование (Ranking)
- Линейная регрессия (Linear regression)
- Перцептрон (Perceptron)
- Иерархическая кластеризация (Hierarchical clustering)
- Кластеризация с использованием K-средних (K-means clustering)
- Нейронные сети (Neural networks)
- Анализ настроений (Sentiment analysis)
- Коллаборативная фильтрация (Collaborative filtering)
- Создание тегов (Tagging)
- Использование метода опорных векторов (Support Vector Machine)
- Обучение с подкреплением (Reinforcement Learning)
Кроме раздела “Основы” дорожная карта исследователя данных содержит еще один ключевой раздел: Интеллектуальный анализ текстов (Text Mining).
- Корпус (Corpus)
- Распознавание именованных объектов (Named Entity Recognition)
- Анализ текста (Text Analysis)
- Архитектура управления неструктурированной информацией (UIMA)
- Матрица термов документов (Term Document matrix)
- Частота и вес термина (Term frequency and Weight)
- Метод опорных векторов (Support Vector Machines: SVM)
- Ассоциативные правила (Association rules)
- Анализ рынка (Market based analysis)
- Извлечение признаков (Feature extraction)
- Использование Mahout (Using Mahout)
- Использование Weka (Using Weka)
- Использование NLTK (Using NLTK)
- Классификация текста (Classify text)
- Сопоставление словарного запаса (Vocabulary mapping)
- Исследование данных в R (Data exploration in R)
- Одномерный, двухмерный и многомерный анализ (Uni, bi and multivariate viz)
- ggplot2
- Гистограмма и круговая диаграмма: Uni (Histogram and pie: Uni)
- Дерево и карта деревьев (Tree & tree map)
- Точечная диаграмма (Scatter plot)
- Линейная диаграмма (Line chart)
- Пространственные диаграммы (Spatial charts)
- График обследования (Survey plot)
- Временная шкала (Timeline)
- Дерево решений (Decision tree)
- D3.js
- InfoVis
- IBM ManyEyes
- Tableau
- Диаграмма Венна (Venn diagram)
- Диаграмма с областями (Area chart)
- Радарная диаграмма (Radar chart)
- Облако слов (Word cloud)
- Основы Map Reduce (Map Reduce fundamentals)
- Экосистема Hadoop (Hadoop Ecosystem)
- HDFS
- Принципы репликации данных (Data replications Principles)
- Настройка Hadoop (Setup Hadoop)
- Имена и узлы данных (Name & data nodes)
- Отслеживание заданий и задач (Job & task tracker)
- Программирование M/R/SAS (M/R/SAS programming)
- Sqop: загрузка данных в HDF (Sqop: Loading data in HDFS)
- Flume, Scribe
- SQL с Pig (SQL with Pig)
- DWH c Hive (DWH with Hive)
- Scribe, Chukwa для веб-блога (Scribe, Chukwa for Weblog)
- Использование Mahout (Using Mahout)
- Zookeeper Avro
- Лямбда-архитектура (Lambda Architecture)
- Storm: Hadoop в реальном времени (Storm: Hadoop Realtime)
- Rhadoop, RHIPE
- RMR
- Базы данных NoSQL: MongoDB, Neo4j (NoSQL Databases: MongoDB, Neo4j)
- Распределенные базы данных и системы: Cassandra (Distributed Databases and Systems: Cassandra)
- Обзор форматов данных (Summary of data formats)
- Обнаружение данных (Data discovery)
- Источники и получение данных (Data sources & Acquisition)
- Интеграция данных (Data integration)
- Объединение данных (Data fusion)
- Преобразование и обогащение (Transformation & enrichment)
- Данных опроса (Data survey)
- Google OpenRefine
- Каковы объемы данных? (How much data?)
- Использование ETL (Using ETL)
- Уменьшение размерности и сокращение чисел (Dim. and num. reduction)
- Нормализация (Normalization)
- Очистка данных (Data scrubbing)
- Обработка пропущенных значений (Handling missing values)
- Объективные оценки (Unbiased estimators)
- Выделение редких значений (Binning Sparse Values)
- Извлечение признаков (Feature extraction)
- Устранение шума (Denoising)
- Отбор примеров (Sampling)
- Стратифицированная выборка (Stratified sampling)
- Метод главных компонент (PCA)
- MS Excel with Analysis toolpack
- Java, Python
- R, Rstudio, Rattle
- Weka, Knime, RapidMiner
- Hadoop
- Spark, Storm
- Flume, Scibe, Chukwa
- Nutch, Talend, Scraperwiki
- Webscraper, Flume, Sqoop
- tm, RWeka, NLTK
- RHIPE
- D3.js, ggplot2, Shiny
- IBM Languageware
- Cassandra, MongoDB
- Microsoft Azure, AWS, Google Cloud
- Microsoft Cognitive API
- Tensorflow
Дорожная карта исследователя данных сопровождается обширными дополнительными ресурсами:
- Бесплатые онлайн-курсы
- 500 проектов в области исследований данных
- 100+ бесплатных книг по машинному обучению
Другие посты по этой тематике см. в моем блоге.