
Вы здесь ▸ Технологии и инструменты ▸

Расчет потерь при оценке качества обучения модели Doc2Vec

Оценка качества модели Doc2Vec
- Генерируем с помощью модели векторы для каждого документа обучающего корпуса, имея в виду, что это новые, то есть не входящие в модель, документы. В Gensim для этого есть специальная функция infer_vector().
- Сравниваем полученные векторы с векторами тех же самых документов, которые входят в модель.
- Вычисляем степень сходства данного документа и а) документа, наиболее похожего на данный и б) документа, следующего за самым похожим на данный. Ожидается, что степень сходства со вторым по похожести документом должна значительно отличаться от степени сходства с самым похожим документом.
Предыдущие исследования
Ранее я уже касался этой проблемы. В том исследовании оценивалось влияние количества итераций (эпох) на качество обучения моделей. В ходе проведенных экспериментов было обучено пять моделей и выполнено сравнение достигнутых уровней потерь. Один из сформулированные выводов — необходимость продолжить исследование для понимания влияния размера вектора документа, минимальной частоты активных слов, скорости обучения на величину потерь.
Функция потерь Loss вычислялась следующим образом:
Loss=N_1/N=1−N_2/N,
N1 и N2 – количество документов корпуса, находящих на 1-й и 2-й позициях соответственно в списке документов, наиболее похожих на данный;
N – общее количество документов корпуса.
Методика расчета потерь
В настоящем исследовании мы усовершенствовали расчет потерь. Теперь используем мультипликативный критерий, включающий в себя два компонента: R – оценка полноты вычисления самоподобия документов и P – оценка точности вычисления самоподобия документов. То есть, уточнили расчет самоподобия документов и учли величину разности между степенями сходства документа с самим собой и следующим наиболее похожим документом.
Выражение для вычисления функции потерь Loss:
Loss=1-R*P=1-(vp_1+b*vp_2)*(\bar{c}_{12}+a),vp1 – доля документов корпуса, наиболее похожих на себя (позиция 1);
vp2 – доля документов корпуса, находящихся на втором месте среди наиболее похожих на себя (позиция2);
c12 – среднее значение разности степеней сходства документа с документами, находящимися на 1-й и 2-й позициях соответственно в списке документов, наиболее похожих на данный;
a – коэффициент, обеспечивающий значение Loss=[0…1], a = 1;
b – коэффициент, учитывающий значимость подмножества документов, определяемого долей vp2, b = 0.5.
Реализация
Фрагмент кода метода класса, который инициирует обучение модели
...
self.model = gensim.models.doc2vec.Doc2Vec(vector_size = self.vectorsize, min_count = self.mincount, epochs = self.epochs, alpha = self.alpha, min_alpha = self.min_alpha)
...
self.model.train(self.train_data, total_examples = self.total_examples, epochs = self.epochs, callbacks = [d2vEpochAssessment(parent = self, docs = docs, docids = docids)])
...Фрагмент кода класса, реализующего callback операции
class d2vEpochAssessment(CallbackAny2Vec):
# Callback to compute assess rank after each epoch.
def __init__(self, parent, docs, docids):
self.epoch = 1
self.docs = docs
self.docids = docids
self.parent = parent
def on_epoch_end(self, model):
if (self.epoch % self.parent.shift) == 0 or self.epoch == 1:
rc = self.parent.set_epoch_vectors(epoch = self.epoch, docs = self.docs, docids = self.docids)
self.epoch += 1 Фрагмент кода функции для сохранения векторов документов для каждой эпохи
def set_epoch_vectors(self, epoch = 0, docs = [], docids = []):
rc = 0
vectors = []
try:
for i, doc_id in enumerate(docids):
inferred_vector = self.model.infer_vector(docs[i])
vectors.append([doc_id, inferred_vector])
self.epoch_vectors[epoch] = vectors
except Exception as e:
rc = 1
return rcФрагмент кода функций для расчета потерь (оценки качества обученной модели)
def assess_model(self):
rc = 0
try:
self.d2v.losses = []
for epoch_number, epoch_vectors in self.d2v.epoch_vectors.items():
epoch_loss = self.d2v.get_epoch_loss(epoch_vectors = epoch_vectors)
epoch_loss['epoch'] = epoch_number
self.d2v.losses.append(epoch_loss)
except Exception as e:
rc = 1
return rcdef get_epoch_loss(self, epoch_vectors = None):
loss_object = {}
model_infern_similarity = 0
vector_pos_1 = 0
vector_pos_2 = 0
c1_minus_c2 = 0
doc_count = len(epoch_vectors)
for epoch_vector in epoch_vectors:
model_doc_vector = self.model.dv[str(epoch_vector[0])]
if len(model_doc_vector) > 0:
infern_doc_vector = epoch_vector[1]
model_infern_similarity = self.model.dv.cosine_similarities(infern_doc_vector, [model_doc_vector])[0]
infern_most_similar = self.model.dv.most_similar(positive = infern_doc_vector, topn = 3)
if str(epoch_vector[0]) == str(infern_most_similar[0][0]):
# Если вектор на 1-й позиции (наиболее похожий) тот же, что сейчас сравнивается
vector_pos_1 += 1
c1_minus_c2 += infern_most_similar[0][1] - infern_most_similar[1][1]
elif str(epoch_vector[0]) == str(infern_most_similar[1][0]):
# Если вектор на 2-й позиции тот же, что сейчас сравнивается
vector_pos_2 += 1
c1_minus_c2 += infern_most_similar[1][1] - infern_most_similar[2][1]
else:
# Если вектор, что сейчас сравнивается отсутствует среди наиболее похожих векторов
pass
vp1 = vector_pos_1 / doc_count
vp2 = vector_pos_2 / doc_count
c1_minus_c2 = c1_minus_c2 / (vector_pos_1 + vector_pos_2) if vector_pos_1 + vector_pos_2 > 0 else 0
c1_minus_c2_plus_a = c1_minus_c2 + self.a if c1_minus_c2 + self.a != 0 else 0.00001
loss_object['loss'] = 1 - ((vp1 + self.b * vp2) * c1_minus_c2_plus_a)
loss_object['vp1'] = vp1
loss_object['vp2'] = vp2
loss_object['c1-c2'] = c1_minus_c2
loss_object['a'] = self.a
loss_object['b'] = self.b
return loss_object Примеры расчета потерь
В ходе проведения экспериментов использовался корпус из 20000 документов, каждый из которых представлял собой текстовое описание книги (заглавие, аннотация, ключевые слова, жанры и т.п.). Значения основных гиперпараметров представлены на графиках. Процедура подготовки исходных данных и обучения стандартные для Doc2Vec.
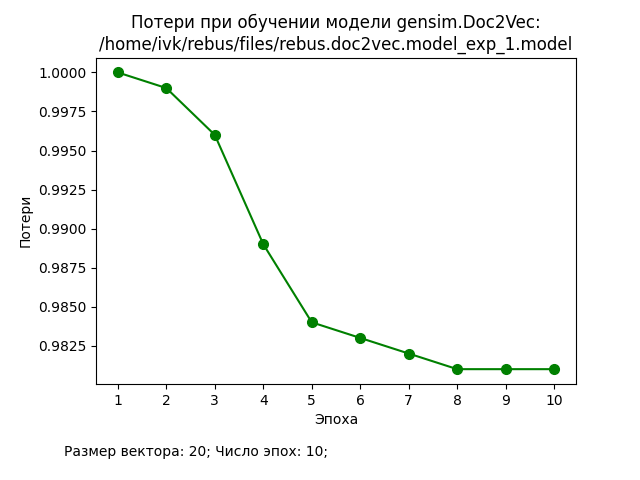
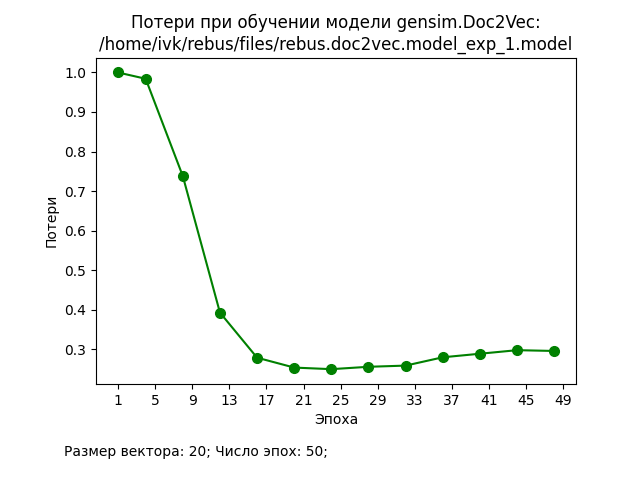
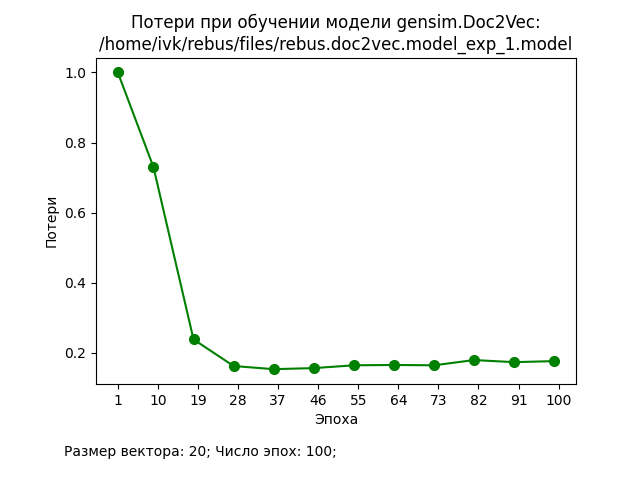
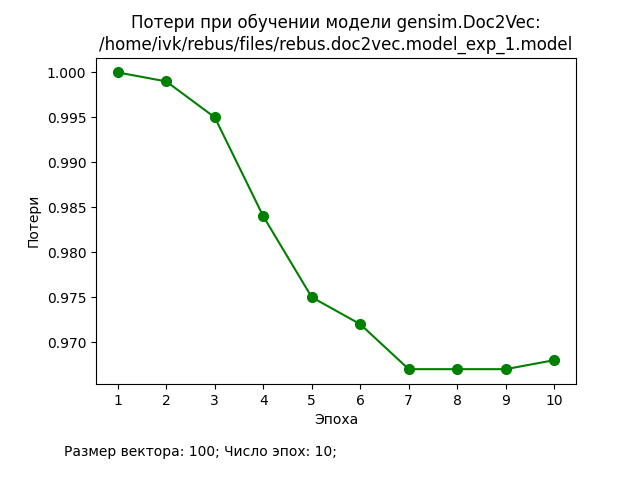
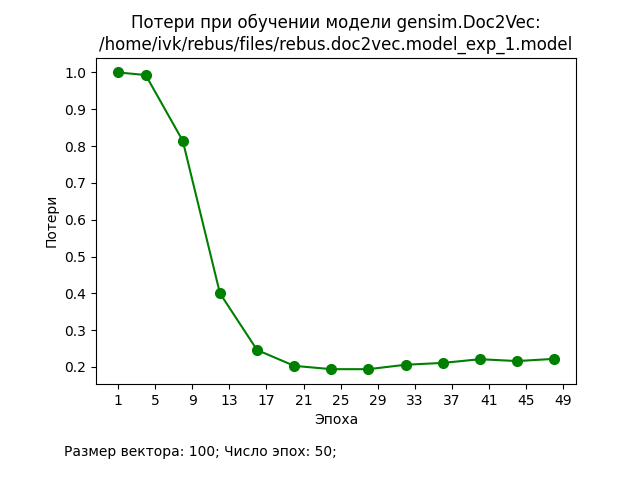
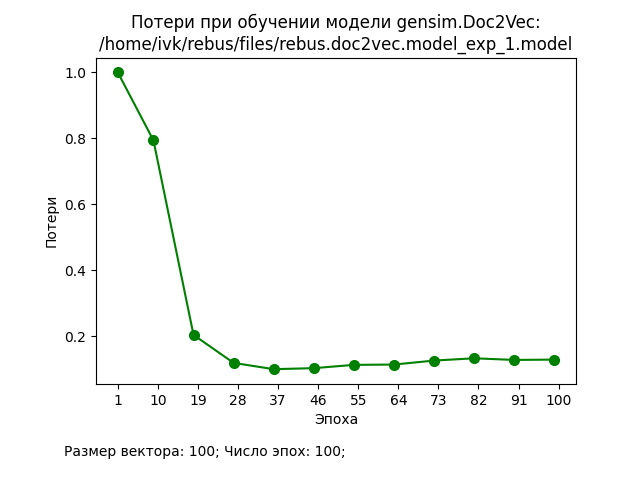
Обсуждение результатов
И делаем общий вывод: предложенная методика расчета потерь позволяет обеспечить приемлемую оценку качества модели Doc2Vec.